 お問い合わせ
お問い合わせ






生成AIの普及により、検索体験は大きく変わろうとしています。Googleの「AI Overview(旧SGE)」やChatGPT、GeminiなどのLLM(大規模言語モデル)は、ユーザーのクエリに対して要約された回答を提示する機能を強化しつつあり、従来のSEOの常識が通用しない場面が増えています。
この変化に対応するために注目されているのが、LLMO(Large Language Model Optimization)=生成AIに「選ばれる情報」になるための最適化です。本記事では、LLMOの基礎から、具体的な最適化アクション、モニタリング・効果測定の方法までを網羅的に解説し、生成AI時代に選ばれるコンテンツ設計のヒントをお届けします。

この記事の重要ポイント
・LLMOは、生成AIに自社コンテンツを選ばせるための最適化手法である
・SEOが検索結果対策なのに対し、LLMOはAIの回答内で参照されることを狙う
・LLMOでは、AIが理解しやすい構造・情報設計が重要になる
・生成AI経由の情報接触が増える中で、新たな露出機会をつくる施策である
シャコウでは、LLMOの基礎となるSEOに関する情報をYouTubeで発信しています。LLMOを理解する上でのベースとなる内容なので、ぜひ参考にご視聴ください。
▼SEO・LLMO対策はやるべき?考え方とモニタリングPDCAに関して徹底解説!

LLMOとは?生成AI時代のSEOの進化系
生成AIが検索体験を変えるなか注目されているのが、LLMO=生成AIに選ばれるための情報設計という新しい考え方です。まずは、LLMOの定義や背景、そして従来のSEOとの違いを確認しましょう。

以下の資料でもLLMOについて詳しく解説していますので、ぜひあわせてご覧ください。
▼資料のダウンロードはこちらから

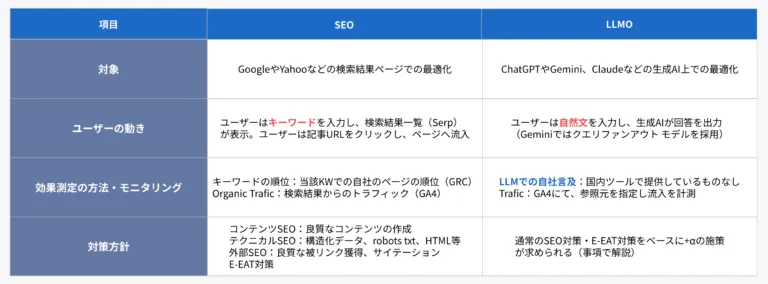
LLMOの定義と背景
LLMO(Large Language Model Optimization)とは、ChatGPTやGemini、Claudeなどの生成AI(LLM)に情報ソースとして選ばれるための最適化手法を指します。
これまでのSEO(Search Engine Optimization)は、GoogleやYahoo!などの検索エンジンにおける検索順位を高めることを目的としていました。しかし、生成AIが普及し、「検索せずに答えが返ってくる」体験が主流になるにつれて、「引用されるかどうか」という新しい軸での可視性獲得が必要になっています。
背景には、GoogleのAI Overview(旧SGE)や、Microsoft Copilotなど、AIによる要約回答が検索体験に溶け込みつつある現状があります。つまり、検索結果ページにクリックされること以上に、AIの出力そのものに情報源として取り上げられることが重要になっているのです。
従来のSEOとの違い
LLMOと従来のSEOの大きな違いは、評価軸が「検索エンジンのアルゴリズム」から「生成AIの出力ロジック」に変化した点にあります。
特に、LLMOにおいては「AIが理解しやすい構造・表現で情報を届けること」が重要です。単にキーワードを盛り込むだけではなく、論理構造や文脈、信頼性の設計までが問われる時代となっています。
▼SEOに関しては以下の記事をご覧ください!

Geminiで使用されているモデル「クエリファンアウトモデル」とは?
LLMOを理解するうえで鍵となるのが、Geminiで使用されているモデル「クエリファンアウト(Query Fan-out)」という生成AIの出力ロジックです。
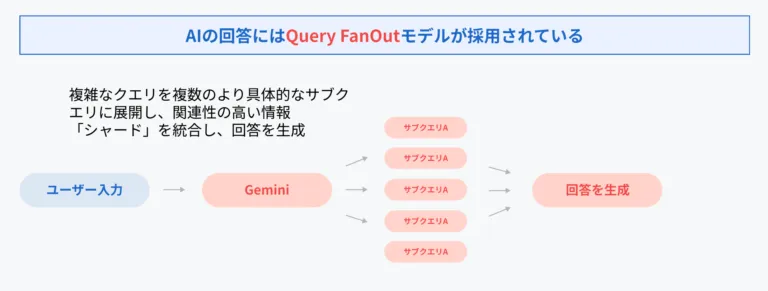
この技術は、ユーザーの質問(クエリ)を複数のサブトピックに分解し、それぞれに対して同時に検索を行います。その結果、従来のGoogle検索に比べてはるかに広く・深くWeb上の情報を探索できるようになり、ユーザーの質問に適した関連性の高いコンテンツを膨大な情報の中から見つけ出すことが可能になります。
このプロセスでは、以下のような段階が含まれます。
- クエリ分解:質問が複数の意図(サブクエリ)に分解される
- 情報検索:その意図に基づき、web上の関連情報が収集される
- 言語モデルによる生成:収集情報をもとに自然言語で回答を出力
つまり、「自社のコンテンツがAIに取り上げられるかどうか」は、構造化や意味づけ、信頼性といった要素が高度に絡みます。
LLMOに取り組むべき理由
従来のSEO施策だけでは、これからの検索トラフィックを十分に獲得できなくなると言われています。ここでは、検索体験の変化や生成AIの仕組み、それによって起きているトラフィック構造の変化から、なぜLLMOが重要なのかを解説します。
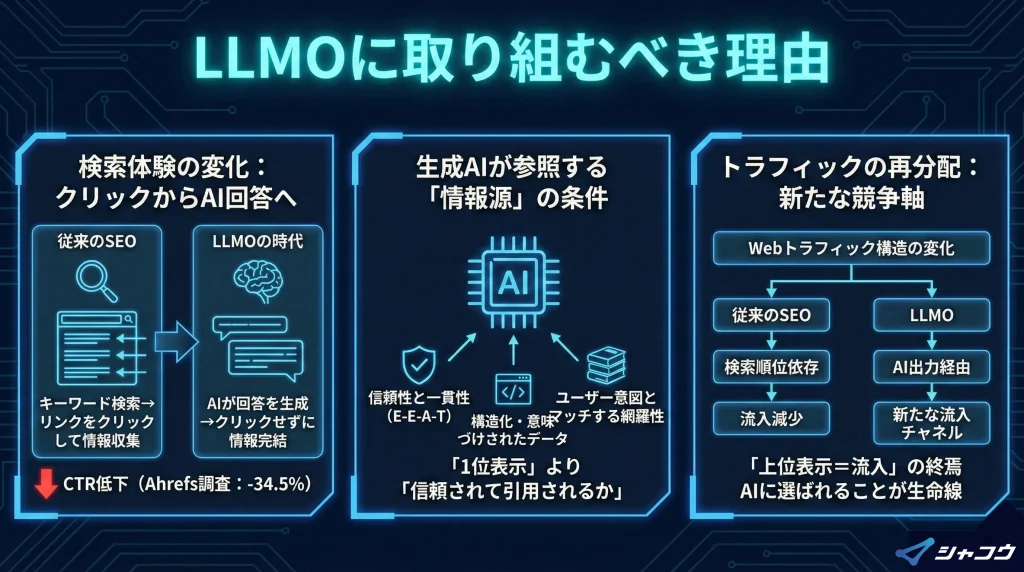
検索体験の変化(AI Overview・生成AIの回答導線)
かつてユーザーは検索エンジンにキーワードを入力し、表示されたリンクの中から自分で情報を選び、遷移して調べるのが当たり前でした。しかし、生成AIの登場により、ユーザーの情報取得体験はリンクをクリックせずに答えが手に入るスタイルへと大きくシフトしつつあります。
具体的には、以下のような検索導線が主流になりつつあります。
- GoogleのAI Overview(旧SGE):検索結果の最上部にAI生成による要約が表示され、クリックせずに情報が完結するケースが増加
- ChatGPTやGeminiのような対話型AI:検索ではなく質問が主軸となり、Web上の情報を横断的に統合して出力
このように、従来の「順位を上げてクリックを稼ぐ」というSEO戦術が効きにくくなる中で、いかにAIに情報ソースとして選ばれるかが新たな競争軸になっています。
実際、Ahrefsが実施した調査によれば、検索結果にAI Overviewが表示されるケースでは、表示されない場合と比較して、上位ページの平均クリック率(CTR)が34.5%も低下することが分かりました。これは、AIによる要約表示がユーザーのクリック行動そのものに強く影響していることを示しており、今後のSEO戦略においても無視できない指標です。
※参照:Ahrefs「AI Overview が表示されることで、ページへのアクセス数が34.5% 減少!」
▼AI Overviewについては以下の記事をご覧ください

生成AIが参照する「情報源」とは何か
では、生成AIはどのような情報を参照して出力を行っているのでしょうか。AIは、検索エンジンと同様にWeb上の情報をクローリング・インデックス化している一方で、出力に使用する情報の選定基準はSEOとは異なります。
主な参照情報の特徴は以下のとおりです。
- 内容の信頼性と一貫性(E-E-A-T:経験・専門性・権威性・信頼性)
- 構造化・意味づけされたデータ(構造化マークアップ、HTMLのセマンティック設計など)
- ユーザー意図とマッチする網羅性(トピックを深く、広くカバーしている)
特に、複数の文書を組み合わせて回答を合成する「クエリファンアウトモデル」では、「一つのページにすべてが載っている」よりも、「信頼できるソースが複数ある」ことが重視されます。つまり、1位表示されるかよりも、「信頼されて引用されるか」がLLMOにおいては本質なのです。
トラフィックの再分配と「選ばれる情報」になる必要性
このような検索体験の変化と、AIが参照する情報の特徴を踏まえると、Webトラフィックの構造自体が変わりつつあることがわかります。
- 「上位表示=流入が取れる」時代は終わりつつある
- 生成AIに「引用される」ことが、新たな流入チャネルとしての重要性を持ち始めている
- 「誰が見つけるか」ではなく「AIが誰を選ぶか」が新たな競争軸
結果として、トラフィックは検索順位のみに依存せず、AIの出力経由で分配される構造へとシフトしています。
このような文脈においては、従来のSEOに加えて「AIへの最適化=LLMO」の視点を持つことが、今後のデジタル施策の生命線になると言えるでしょう。

BtoBコンサルタント
柴犬先輩
生成AIによる検索が主流になってきているからこそ、LLMOへの対策も必要なんだ!
LLMOにおける最適化の方向性
LLMOに取り組むうえで基本となるのは、従来のSEO対策に加え、生成AIに選ばれる情報として認識されるためのプラスαの工夫です。ここでは、最適化の方向性を3つの観点から整理し、それぞれの施策ポイントを紹介します。
.webp)
Web上のコンテンツの充実
まず重要なのが、ユーザーの検索意図(メインクエリ)だけでなく、それを細分化した「サブクエリ」にまで対応したコンテンツの整備です。生成AIは、1つのクエリに対して複数の質問や視点(サブクエリ)を展開する「クエリファンアウトモデル」に基づいて出力を構成するため、表層的な網羅だけでは情報源として選ばれにくくなります。
また、特定の業界ニーズや導入事例など、尖ったニーズに応えるエッジの効いたコンテンツも有効です。これにより、特定のユースケースや業界文脈に強いサイトとして、生成AIに引用されやすくなります。
この領域は、継続的なコンテンツ強化とサブクエリごとのギャップ分析によってPDCAを回す必要があります。
E-E-A-T・外部対策
次に、信頼性の証明と外部評価の獲得も重要なポイントです。生成AIは検索エンジンと同様に、コンテンツのE-E-A-T(経験・専門性・権威性・信頼性)を重視しています。特に、BtoB領域や、医療・法律・金融といった専門領域では、誰が言っているか(著者性)や、どのサイトに引用されているか(外部評価)が選ばれる条件に直結します。
具体的には、E-EATを強化するには以下のような対策が必要であるとされています。
- 業界キーワードのサブクエリで上位表示されている媒体への寄稿・取材掲載
- 著者情報の明記や、専門家監修など信頼の証を明文化する
- 被リンク・SNS引用など、外部シグナルの強化
この領域もまた、モニタリングと改善の継続(PDCA)が不可欠です。
AIに読み取りを助ける対策(構造化・HTML・サブクエリ対応)
最後に、AIに「意味を正しく伝える」ための技術的施策(テクニカル)です。生成AIはHTML構造や構造化マークアップを読み取りながら意味理解を行うため、技術的な整備がされていないと、内容の良し悪し以前に参照対象に含まれない可能性があります。
具体的には、主に以下のような施策が必要です。
- 構造化マークアップの最適化(FAQ・記事・人物・商品など適切なスキーマの活用)
- HTMLタグのセマンティクス設計(hタグ・section・articleなどの論理構造)
- SSR(Server Side Rendering)など、AIに読み取られやすい出力形式の採用
これらは比較的一度の改善(ショット改善)で効果が期待できる領域ではありますが、サイト構造変更やリニューアルの際には再度チェックが必要です。
LLMO実践ガイド|生成AIに選ばれるための10の最適化アクション
従来の順位争いではなく、「引用される価値があるかどうか」が評価軸に変わりつつある中、私たちは新たな最適化の軸を理解し、具体的なアクションに落とし込む必要があります。ここでは、LLMOに対応するために取り組むべき10の実践的アクションを紹介します。

① llms.txtの設置と構成の最適化
Googleなどのクローラーにおけるrobots.txtのように、OpenAI・Anthropicなどの生成AIが参照する「llms.txt」を用意することで、AIに対して「自社サイトを積極的に読み込んでほしい」という意思表示が可能になります。
しかしこれは、設置場所や記述ルールは現状統一されておらず、標準化された仕様ではないことは留意しておくべきです。例えば、GoogleのSearch AdvocateであるJohn Mueller氏は「現在 AI システムでは llms.txt は使用されていません。」と明言しています。
FWIW no AI system currently uses llms.txt.
llms.txtの設置に関しては、今後も業界の動向を見ながら対応していく必要があります。
② サブクエリレベルでの情報設計とコンテンツ充実
生成AIは、ユーザーの質問を複数の「サブクエリ(派生質問)」に分解し、それぞれに答えられる信頼情報を集めます。このため、トピック単位ではなくサブクエリ単位で情報を網羅する設計が求められます。
例えば「LLMOとは?」に加えて、「従来SEOとの違い」「事例」「実装方法」など周辺の疑問にも対応したページを整備することで、AIが拾いやすい部分的な回答ソースになれます。
③ 導入事例や業界特化コンテンツなどエッジ情報の強化
業界固有の課題や導入実績といった、他では得られない一次情報やエッジ情報は生成AIにとっても貴重なリソースです。
たとえばBtoB分野では、「業界名+課題」などのロングテールサブクエリに応えるページを用意し、権威性や独自性を示すことで引用可能性を高められます。
④ 構造化マークアップと意味理解の強化
AIにとって「意味」が伝わりやすい記述形式でコンテンツを整理するために、構造化マークアップ(schema.org)を活用することは有効です。構造化マークアップとは、コンテンツを適切に理解しやすいようにHTMLの中にタグを加えることです。
FAQ・レビュー・記事・製品情報など、該当する構造に沿ってマークアップを行えば、意味の明確化とともにAIへの認識精度向上が期待できます。
⑤ HTML設計・SSRなどAIに読み取られやすい技術対応
動的に生成されるコンテンツやJavaScript中心の構成は、AIクローラーの読み取りを妨げる可能性があります。
そこで、HTMLソースに主要な情報が露出している設計(SSR:サーバーサイドレンダリングなど)や、冗長なコードを避けたシンプルなマークアップが推奨されます。
⑥ サイトスピード・表示パフォーマンスの最適化
AIモデルがユーザー体験まで把握するわけではありませんが、コアウェブバイタル(CWV)などを含むパフォーマンス指標は、全体評価に間接的に影響を与える可能性があります。
また、人間ユーザーのエンゲージメント(直帰率、滞在時間等)にも関わるため、ページの高速表示と安定性の担保は引き続き重要です。
⑦ AIが理解しやすい記事構成と見出し設計
AIは人間と同じように「論理構造」や「トピックの区切り」を重視します。H2・H3の階層設計や、見出しにキーワードを含める工夫、パラグラフごとの情報の粒度を揃えるといった設計が、理解を助けるポイントです。
また、1見出し1トピックの原則を守ることで、回答ソースとして引用されやすくなります。
⑧ 文章表現の最適化(簡潔さ・文脈理解)
AIは複雑な文よりも、簡潔かつ明快な文構造を好む傾向にあります。主語・述語が遠くならないよう調整し、冗長な接続語や抽象表現を避けることで、理解しやすさが向上します。
また、「〇〇とは」→「〇〇は〜である」のような定義形式の文章は、生成AIの回答パターンと親和性が高く、冒頭要約への引用率が上がる傾向もあります。そのため、必要に応じてH2見出しを「〇〇とは」といった形式にするのも有効な策です。
⑨ E-E-A-T強化による信頼性の明示
生成AIが情報の信頼性を評価する際、「誰が書いたか(経験・専門性)」「どこで書かれたか(組織)」「その人の評判や外部リンク」などを参照します。
著者情報や監修情報の明記、会社プロフィールページの整備、ソーシャルメディアやメディア露出の外部証跡強化が求められます。
⑩ サブクエリ上位記事への掲載・被リンク獲得など外部対策
AIが「参考」とする情報源は、被リンク数や他メディアへの掲載状況などの外部シグナルによって評価される側面もあります。
そのため、サブクエリ関連ワードで上位表示されている他記事における掲載・協業や、信頼性のある被リンクの獲得を意識的に行っていくことが重要です。
LLMO改善のモニタリングとオペレーション
LLMOは一度の施策で完結するものではありません。SEOと同様に、継続的なモニタリングと改善サイクル(PDCA)が必要です。まずは、どのように生成AI内での自社の言及状況をモニタリングし、改善につなげるかについて、実践的な手順を紹介します。

1. ペルソナベースでの前提条件を設定する
まずは、生成AIが参照する状況をシミュレーションするために、想定するユーザー像(ペルソナ)を明確に設定します。
例:
- 業界:コンサルティング会社
- 従業員数:90名
- 役職:部長クラス
- 課題:CRMが形骸化しており、SFA/CRMを刷新したい
こうした前提をもとに、自然文の検索クエリ(プロンプト)を設計していきます。
2. 解像度の高いクエリを設計する
次に、実際の検索ニーズに近い自然文のクエリを設計します。SEOにおけるキーワード設計に近い工程ですが、より会話調・文脈依存の設問になります。
例:
- おすすめの顧客管理システムは?
- コンサル業界で人気のCRMを教えてください
- 中小企業向けでコスパの良いSFAはありますか?
- ◯◯と連携できるCRMを探しています
このように、業界・企業規模・課題・機能などの要素を組み合わせて多角的なクエリを生成します。
3. モデルごとの出力結果を取得する
クエリが整ったら、複数のLLM(生成AI)に入力し、回答結果を収集します。モデルによって回答内容が大きく異なるため、以下のように複数のモデルを横断的に観察することが重要です。
例:
- ChatGPT-4o(OpenAI)
- Gemini 1.5(Google)
- Claude 3(Anthropic)
同一クエリでも、モデルの学習データ・検索ベース・UI設計の違いにより、引用元や回答スタイルにばらつきが出ます。
4. 言及率・競合比較のモニタリング
収集した回答結果をもとに、以下の視点で定量・定性のモニタリングを行います。
- 自社が回答内で言及されているか(自然文中 or 引用リンク)
- 同じ質問に対して、競合がどれくらい登場しているか
- クエリのジャンル別(業界特化・価格比較・機能訴求など)に強弱があるか
- モデルごとの言及傾向の差
たとえば、25種類のクエリ × 3モデル=75回答を定点記録し、日別の変化や競合の出現傾向もログ化していくのが理想的です。
5. 言及改善に向けた施策立案とPDCA
モニタリングの結果、自社が特定ジャンルのクエリで言及されない場合、その分野での認知獲得やエビデンスの補強施策を検討します。
例:
- コンサル業界クエリで言及が弱い → 業界別導入事例ページを作成
- コスパ訴求のクエリで他社に負けている → 比較表の作成や価格訴求コンテンツを整備
- 競合が登場するメディアがある → その媒体への掲載交渉や引用対策を実施
また、AIが参照しているSerp(検索結果)記事を特定し、自社の掲載を働きかけることも効果的です。
BtoBコンサルタント
柴犬先輩
LLMOはSEOと同様に、継続的なモニタリングと改善サイクルが必要だぞ!
LLMOモニタリングとPDCAの具体例
LLMOにおける最適化は「施策を打つこと」だけで完結するものではありません。生成AIがどのようなロジックで回答を生成しているかを観察し、その結果に応じて改善策を立てることが不可欠です。
ここでは、具体的なモニタリング方法と、それに基づくPDCAサイクルの回し方を紹介します。
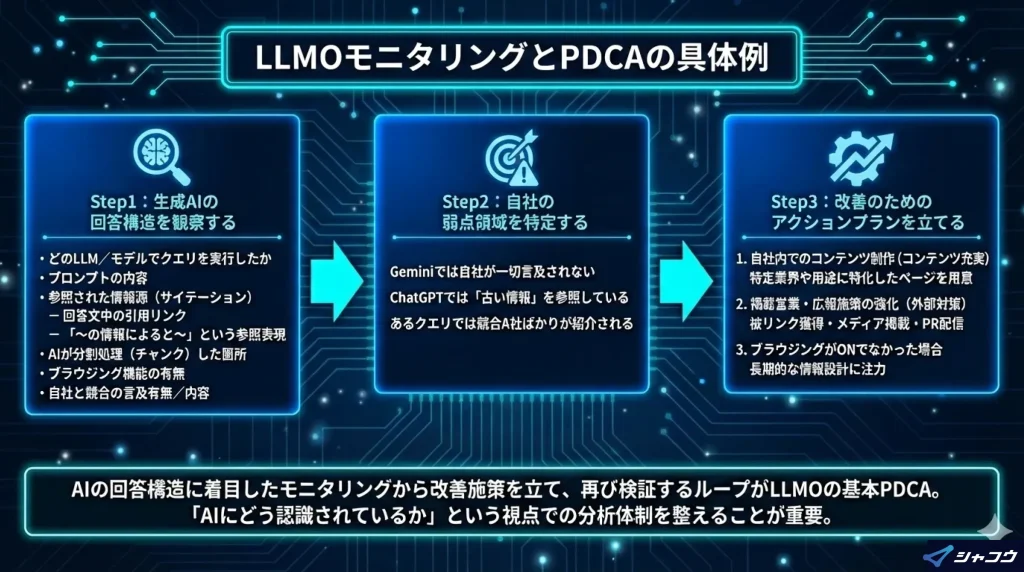
Step1:生成AIの回答構造を観察する
まずは、LLM(Large Language Model)がどのようなプロンプトに対して、どんな根拠で回答を返しているのかを観察します。
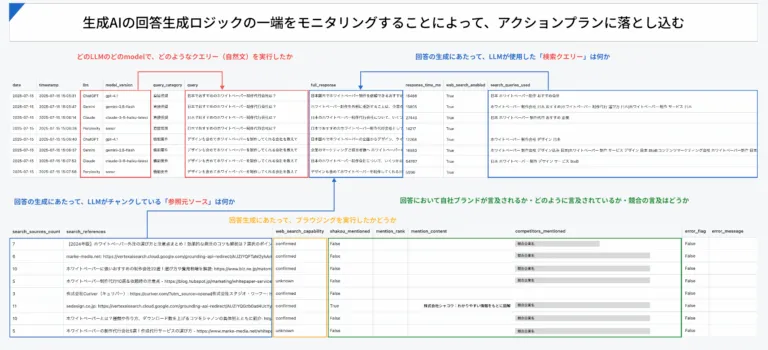
以下のような視点で出力結果を記録しましょう。
・どのLLM/モデルでクエリを実行したか(例:Gemini 1.5、ChatGPT-4oなど)
・プロンプトの内容(例:中小企業向けCRMのおすすめは?)
・参照された情報源(サイテーション)
– 回答文中の引用リンク
– 「〜の情報によると〜」という参照表現
・AIが分割処理(チャンク)した箇所
– 特定の文脈を小分けにして使っている痕跡があるか
・ブラウジング機能の有無
– 生成時に「最新情報取得モード」がONだったか
・自社と競合の言及有無/内容
– ブランド名が出たか?どう紹介されたか?
– 競合はどこが登場したか?その評価内容は?
これらを整理することで、AIの判断材料に自社コンテンツが含まれているか否かが明確になります。
Step2:自社の弱点領域を特定する
たとえば、以下のような現象が見られる場合は改善対象となります。
- Geminiでは自社が一切言及されない
- ChatGPTでは「古い情報」を参照している
- あるクエリでは競合A社ばかりが紹介される
このような差分を発見することで、次のアクションに繋げやすくなります。
Step3:改善のためのアクションプランを立てる

生成AIの言及状況から以下のような改善施策が考えられます。
1. 自社内でのコンテンツ制作(コンテンツ充実)
これまでSEOでは「検索ボリュームが少ない」と判断して書かなかったキーワードも、AI回答においては必要コンテンツである可能性があります。特定業界や用途に特化したページ(例:◯◯業界向けCRM導入事例)を用意しましょう。
2. 掲載営業・広報施策の強化(外部対策)
AIが参照している媒体(比較サイト・業界記事など)を特定し、自社の掲載や言及を促進する活動を行います。被リンク獲得・メディア掲載・PR配信などがここに該当します。
3. ブラウジングがONでなかった場合
モデルがブラウジングせず、知識カットオフ(学習時点での情報)だけで回答している場合は、 「今すぐの対策は不要」と判断するのも一つの選択肢です。その代わり、学習フェーズに影響を与える長期的な情報設計に注力します。
このように、AIの回答構造に着目したモニタリングから改善施策を立て、再びAIの出力で検証するというループが、LLMOの基本的なPDCAです。単に「SEO順位」だけを見るのではなく、「AIにどう認識されているか」という視点での分析体制を整えることが重要です。
LLMOに関するよくある質問
Q1. LLMOと従来のSEOは何が違う?
A. SEOは検索エンジン結果での上位表示を目的とした最適化であるのに対し、LLMOは生成AI(ChatGPT・Google AIなど)の回答内で自社コンテンツが引用・参照されることを狙う最適化です。
Q2. なぜ今LLMOへの対策が必要?
A. 生成AIによる検索体験が増え、ユーザーがAIの回答で情報を得る機会が増えているため、AIに認識・引用されるコンテンツにならないとWebでの露出機会や集客機会を失う可能性があるからです。
まとめ|LLMOを理解し、生成AI時代に選ばれるコンテンツを目指そう
従来のSEO対策は「検索エンジンでの上位表示」に主眼が置かれていましたが、生成AIの普及によって“選ばれる情報”の基準が変化しつつあります。LLMOは、まさにこの変化に対応するための新たな最適化の視点です。
本記事では、LLMOの基本概念から従来SEOとの違い、最適化の具体施策、効果測定・運用方法までを解説しました。重要なのは、単にAIに拾われやすい構造にすることではなく、「信頼される・意味がある」情報としてAIに引用される状態を目指すことです。
選ばれるコンテンツには、以下のような要素が総合的に求められます。
- 高品質な内容(ユーザーにとって有益)
- 文脈の明瞭さ(AIにとって理解しやすい)
- 信頼性(E-E-A-Tの担保)
- テクニカルな正しさ(構造化・スピード最適化)
LLMOは、SEO・コンテンツ・広報・データのすべてが関係する横断的な取り組みです。生成AI時代の新たな情報戦を勝ち抜くためにも、戦略的な設計と運用体制が重要です。
戦略設計・実行支援は「シャコウ」にご相談ください
LLMOやSEOの戦略設計にお悩みなら、シャコウが一気通貫でご支援します。私たちは、戦略から実行、運用・改善までを視野に入れた「AI時代の情報設計支援」を提供しています。以下のような課題をお持ちの方は、ぜひお気軽にご相談ください。
- LLM最適化にどう取り組めばいいか分からない
- AI Overviewや生成AIで自社が選ばれない理由を知りたい
- SEOと生成AI最適化を統合的に設計・改善したい
- マーケティングと営業が連動した体制を築きたい

BtoB領域に特化したマーケティング・セールス支援を強みとする私たちシャコウが、SEO・LLMOに関する上流設計、実行、コンテンツ・テクニカル・外部SEO・LLMOといった総合的なSEO・LLMOに貢献し、御社の事業推進を伴走型でサポートします。ぜひお気軽にご相談ください。
















新卒BtoBマーケター
白ポメちゃん
生成AIが使われるようになったからLLMOが注目されてるんですね!
でもなんでLLMOに取り組んだほうがいいの〜??